
This is part of the transcript of a talk I gave at The Developer Conference in Porto Alegre. You can find the deck online
I broke the transcript in several part that can be read independantly:
- Part 1: SOA Services in 5 minutes
- Part 2: Scaling your business
- Part 3: No microservices without ownership
- Part 4: Data architecture for microservices
- Part 5: Operability in microservices world
- Part 6: Anti-fragile system
- Part 7: Agile coaching for successful microservices system
- Part 8: Existing microservices stacks
Operability in microservices world
Operating such a complex architecture is challenging and require a lot of work. Automation just won’t be enough!
A good start to keep things operable is to follow the 12 Factors good practices. Some recommandations might heart your feelings because it goes against the way you worked until now. However those recommendation usually help keeping the system running.
Normalization
If you need to keep only one idea out of this part, it must be normalization. The number of service will grow quickly and potentially the number of developer involved too. You cannot afford every team doing everything the way they think is best. You need to force some patterns. It doesn’t mean you won’t leave choices to every team. It means that you will need them to use some common tools that makes the whole system reliable, manageable, recoverable and some other “able” properties.
Skeleton
A good start is to provide a full stack skeleton for every language you want to support. It means that you provide to the teams a hello world project from database to UI with yet a certain level of test. It yet has configured the parts that you want to see in every project. It includes the choice of web server. You want teams spending as much time as possible on business stuff. This skeleton project will automatically use the service configuration system of your choice. It could be Archaius from Netflix, which is built on top of apache configuration common, etcd, zookeeper or the solution that comes with spring cloud. The critical part, is that you want to be able to reconfigure everything with never restarting the service. Any configuration system that doesn’t let you do this isn’t good enough. Configuration can change at any point in time, and you don’t want downtime :)
Discovery
You don’t want services knowing the host and ports of other components. You obviously can start with a static list at the beginning of the project, very quickly, it won’t scale. Some options are Eureka, from Netflix. It is a simple war file, so in can run locally. Its only dependency to AWS is how services discover it: using static DNS based on EIP. It also relies on Auto Scaling Group to always have at least on instance running per AZ. Today, there are several open source options that could help you solve those issues outside AWS. However, discovery service can be seen as a metadata service, hence etcd, zookeeper and Mesos DNS can also have the role of service discovery. Another solution is Consul.
Inter service communication
They way services call each other is critical for performance and resiliency. You don’t want every team coding fallbacks and retry handlers differently. You want to use a library that will simplify this for every team. Histryx with Ribbon are very good options as it open a lot of options in term of configuration and even provide monitoration. Hystrix implements the circuit breaker pattern avoiding cascading effect of an unhealthy service.
Edge services
The next part is how clients find your services from the Internet. You don’t want every device targetting directly your internal services. That’s why you need an edge service that will cumulate a couple of roles: it will be a proxy that will route requests to the proper service, using the service discovery component. It will also cache whatever it can and protect the system from potential attacks. Don’t get me wrong on this part. Security needs to happen at every level of this architecture, including in internal services. However certain type of attack should be blocked at the edges of the system.
Logs and monitoring
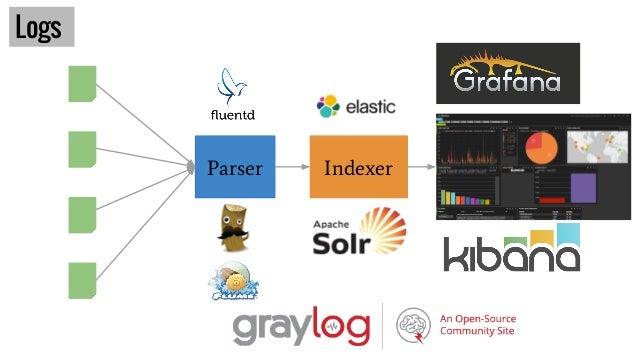
The more complex is your system, the more you need indicators to understand how it behaves. There are litterally millions of parameters that you may want to monitor. However, a good start is my centralizing logs. Solutions are made of four parts: 1. an agent that keeps reading log files 2. a parser that will understand the log format and transform it to a structured form like json 3. an indexer to be able to look for logs 4. a vizualization tool to create as many vizualizations as possible
Logs are good indicator but doesn’t cover everything. You will also need to use agents on server to monitor OS related metrics and other platform specific metrics. At some point, you will also want to be able to trace the route of specific messages inside the system in order to know which service it went through and how much time it spent into it. Zipkin let you centralize information to vizualize this kind of information.
Deploy
It is now kind of obvious, but deploy must also be normalized. Today there are many tools to perform that. A good deploy pipeline will end creating a container. It can be an AMI for AWS, a Docker container or anything that your platform will understand as long as it contains the operational system and the running application. With this kind of pipeline you abstract your infrastructure and can start managing it the same way you manage your code. Everything can be versionned, created and destroyed.
What you need is provide your teams a self service platform where they can easily choose a stack, find where to put their code and quickly understand how to use it, run it, deploy it, maintain it… Yes, to achieve this, you will need to work closely with operation team.