
This is part of the transcript of a talk I gave at The Developer Conference in Porto Alegre. You can find the deck online
I broke the transcript in several part that can be read independantly:
- Part 1: SOA Services in 5 minutes
- Part 2: Scaling your business
- Part 3: No microservices without ownership
- Part 4: Data architecture for microservices
- Part 5: Operability in microservices world
- Part 6: Anti-fragile system
- Part 7: Agile coaching for successful microservices system
- Part 8: Existing microservices stacks
Data architecture for microservices
One of the part of Microservices architecture usually scaring the most technical people, is splitting their current monolith database into smaller databases. The task looks impossible and daunting. All data is stored into tables with primary keys and foreign keys. The problem is simple, you have core entities that are referenced by different parts of the business. Let’s look at the product entity example. In a micro service architecture I would probably have a Product service responsible for keeping track of the existing products and a Pricing service responsible to compute the price of product taking taxes and promotions into account. The pricing service will probably stores basic information of the product. The problem happen when we want to update one those basic information, let’s say the name of the product.
First potential solution
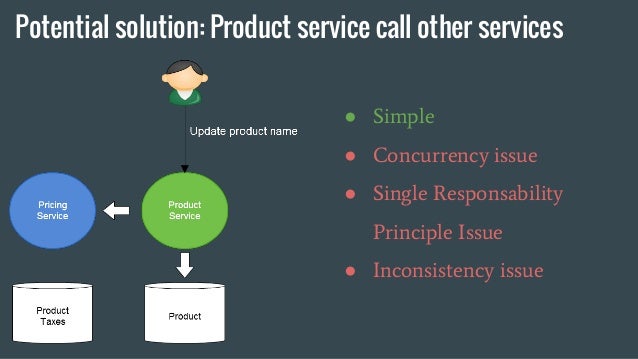
The Product service receive the update call, update its database and call the Pricing product to notify the update. This solution is simple. Nevertheless it has a couple of pitfalls: * concurrency issues: several updates on the same entity with latency irregularity can mess up with the order updates arrive and are computed by the pricing service * Single Responsability Principle is being violated: in this solution Product service needs to keep track of the services it needs to update. * Inconsistency issues: the concurrency issue can create inconsistencies between data stored by the product service and the pricing service
Second potential solution
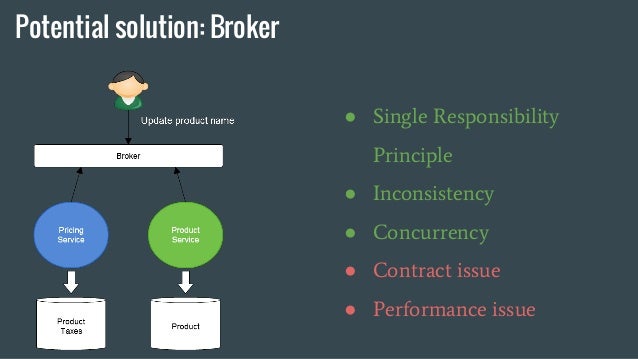
In order to respect the Single Responsabilty Principle and avoid concurrency issue, we can put a broker in front of Product and Pricing service. With this architecture, Product service doesn’t know about Pricing service anymore. As update events arrive in the same order for both services, we don’t have concurrency and consequently inconsistency issues. However, we start having contract issues. As Product and Pricing services now expose the same contract for product update, both team need to agree on a common contract. Product update doesn’t make much sense in the pricing service, so the solution start looking clumsy.
Third potential solution

This time, we don’t allow product to directly update its database. Instead it publish a product update to a broker. If any service is interested by product update, it will create a worker to subscribe to the topic. Product servce and Pricing service keep accessing their database directly when it comes to read, however write go through this broker. The main issue with this solution is the complexity it adds, because developper stop thinking in updating state and start thinking in publishing events. Moreover, there is added latency between the moment the service publish an update and the moment it actually happen in database which can cause some temporary inconsistences on a client point of view. Complex transactions becomes a lot more complex in this scenario.
CQRS
What this example highligh is a need to change the way we think about data. It forces to create a data architecture that uses CQRS ideas. This is necessary because otherwise teams will need to synchronize their work with the work done on database side.
Shared mutable state
At the end of the day, when we decide to distribute services and their databases, we start dealing with shared mutable state. This is one of the hardest problem of computer science. The best way I know to deal with it, is using core Functional Programming concepts: Immutable data structure and Pure Functions. This is how big data problems are being solved, how RDBS work internally (they use an append only log file for replication) and how consencus alorithms like Raft work. My advise is to use as much functional programming concepts as you can when designing your data architecture.
Eventual consistency
This is inevitable, you will start having temporary consistency issues between services. There is no easy solution on how to handle it. In this case, I would recommend being creative and checking with business where the real bounds are. In the case of a money transfer, the bank just charge its client if they manage to draw more money than they have. They allow eventual consistency and make the client responsible for not abusing it. Don’t always look for technical solution to technical problems, sometimes the solution can be found on the business side.
